Text-to-Speech AI
Ubah teks menjadi ucapan yang terdengar alami menggunakan API yang didukung oleh teknologi AI Google terbaik.
Pelanggan baru mendapatkan kredit gratis senilai hingga $300 untuk mencoba Text-to-Speech dan produk Google Cloud lainnya.
Tingkatkan interaksi pelanggan dengan respons yang cerdas dan terdengar nyata
Ciptakan interaksi pengguna dengan antarmuka pengguna suara di perangkat dan aplikasi Anda
Personalisasikan komunikasi Anda berdasarkan preferensi suara dan bahasa pengguna
Manfaat
Ucapan berakurasi tinggi
Deploy teknologi inovatif Google untuk menghasilkan ucapan dengan intonasi layaknya manusia. Dibangun berdasarkan keahlian sintesis ucapan DeepMind, API tersebut memberikan suara yang mendekati kualitas suara manusia.
Pilihan suara terluas
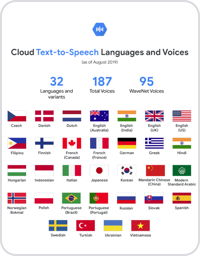
Tersedia pilihan lebih dari 380 suara dalam lebih dari 75 bahasa dan varian, termasuk Mandarin, Hindi, Spanyol, Arab, Rusia, dan banyak lagi. Pilih suara yang paling sesuai untuk pengguna dan aplikasi Anda.
Suara yang unik
Buat suara yang unik untuk mewakili brand Anda di semua poin kontak pelanggan Anda. Jangan menggunakan suara yang sama dengan yang dipakai organisasi lain.
Demo
Menerapkan Text-to-Speech
Ketik apa saja, pilih bahasa, lalu klik “Ucapkan” untuk mendengarnya.
Fitur utama
Fitur utama
Gemini-TTS
Lakukan sintesis ucapan satu atau banyak penutur dari cuplikan pendek hingga narasi panjang, dengan tetap mempertahankan kontekstualitas. Tentukan gaya, aksen, kecepatan, nada, dan ekspresi emosional dengan tepat dengan perintah bahasa alami sederhana dalam lebih dari 75 lokalitas. Buka Media Studio atau lihat dokumentasi kami untuk mempelajari lebih lanjut.
Chirp 3: Suara HD
Bangun agen yang menarik menggunakan suara percakapan spontan terbaru yang berbasis AudioML. Suara ini menawarkan audio berkualitas tinggi, streaming berlatensi rendah, dan ucapan yang terdengar alami, dengan intonasi yang akurat, beragam emosi, serta menyertakan ketidaklancaran pengucapan manusia. Buka Media Studio atau lihat dokumentasi kami untuk mempelajari lebih lanjut.
Chirp 3: suara kustom instan
Buat model suara yang dipersonalisasi hanya dengan input audio berdurasi 10 detik. Cocok untuk video game, buku audio, podcast, dan lainnya. Tersedia dalam lebih dari 30 lokalitas. Buka Media Studio atau lihat dokumentasi kami untuk mempelajari lebih lanjut.
Dukungan perintah, teks, dan SSML
Kontrol format angka dan waktu, pengiriman, pengucapan, dan emosi menggunakan pembuatan skrip teks biasa yang sederhana, tag SSML, atau bahkan perintah bahasa alami yang canggih, tergantung model yang didukung. Buka Media Studio atau lihat dokumentasi kami untuk mempelajari lebih lanjut.
Yang baru
Yang baru
Daftar untuk berlangganan newsletter Google Cloud guna menerima berita terbaru terkait produk, informasi acara, penawaran spesial, dan lainnya.




Dokumentasi
Kasus penggunaan
Kasus penggunaan
Voicebot di pusat kontak
Berikan pengalaman suara yang lebih baik bagi layanan pelanggan menggunakan voicebot di Dialogflow yang dapat menghasilkan ucapan secara dinamis, bukan memutar audio statis hasil rekaman. Berinteraksilah dengan suara sintesis berkualitas tinggi yang memberi penelepon rasa familiar dan personalisasi.
Pembuatan suara di perangkat
Aktifkan komunikasi alami bersama pengguna Anda dengan mendukung perangkat untuk mengucapkan suara layaknya manusia sebagai pembaca teks. Bangun antarmuka pengguna suara end-to-end menggunakan Speech-to-Text dan Natural Language untuk meningkatkan kualitas pengalaman pengguna dengan interaksi yang mudah dan menarik.
EPG (Panduan Program Elektronik) ramah difabel
Buat EPG membacakan teks dengan lantang untuk memberikan pengalaman pengguna yang lebih baik kepada pelanggan Anda dan memenuhi persyaratan aksesibilitas untuk layanan dan aplikasi. Coba demo EPG.
Implementasikan fungsi text-to-speech dengan mudah di EPG untuk memberikan pengalaman pengguna yang lebih baik kepada pelanggan Anda dan memenuhi persyaratan aksesibilitas untuk layanan dan aplikasi.
Semua fitur
Semua fitur
| Sintesis audio streaming | Dukung agen AI Anda dengan ucapan berlatensi ultra-rendah untuk memproses percakapan real-time yang lancar dengan sintesis audio streaming. |
| Sintesis audio panjang | Lakukan sintesis hingga 1 juta byte input secara asinkron dengan sintesis audio panjang. |
| Pemilihan suara dan bahasa | Tersedia lebih dari 380 suara yang dapat dipilih dalam lebih dari 75 bahasa dan varian, dan jumlahnya akan bertambah dalam waktu dekat. |
| Dukungan Teks dan SSML | Sesuaikan ucapan dengan tag SSML yang memungkinkan Anda menambahkan jeda, nomor, format tanggal dan waktu, serta petunjuk pengucapan lainnya. |
| Penyesuaian tinggi nada | Personalisasikan tinggi nada suara yang Anda pilih, hingga 20 semitone di atas atau di bawah setelan default. |
| Penyesuaian kecepatan bicara | Sesuaikan kecepatan bicara menjadi 4x lebih cepat atau lebih lambat dari kecepatan normal. |
| Kontrol peningkatan volume | Tingkatkan volume output hingga 16 dB atau kurangi volume hingga -96 dB. |
| REST API dan gRPC API terintegrasi | Mudah diintegrasikan dengan aplikasi atau perangkat apa pun yang dapat mengirimkan permintaan REST atau gRPC, termasuk ponsel, PC, tablet, dan perangkat IoT (misalnya, mobil, TV, speaker). |
| Fleksibilitas format audio | Ubah teks menjadi format MP3, Linear16, OGG Opus, dan sejumlah format audio lain. |
| Profil audio | Optimalkan jenis speaker yang digunakan untuk memutar ucapan Anda, seperti headphone atau saluran telepon. |
Harga
Harga
Text-to-Speech dikenakan biaya berdasarkan jumlah karakter yang dikirim ke layanan untuk disintesis menjadi audio setiap bulannya. 1 juta karakter pertama per bulan gratis untuk suara WaveNet. Untuk suara Standar (non-WaveNet), 4 juta karakter pertama per bulan gratis. Setelah batas paket gratis tercapai, Text-to-Speech akan dikenakan biaya per 1 juta karakter teks yang diproses.
Jika Anda melakukan pembayaran dengan mata uang selain USD, yang berlaku adalah harga yang tercantum dalam mata uang Anda pada SKU Google Cloud.
Langkah selanjutnya
Pelanggan baru mendapatkan kredit gratis senilai $300 untuk mencoba Text-to-Speech dan produk Google Cloud lainnya.
Perlu bantuan untuk memulai?
Hubungi bagian penjualanBekerja sama dengan partner tepercaya
Temukan partnerLanjutkan menjelajah
Lihat semua produk